

可迁移的高可用点赞系统实现-下
4.点赞功能改进
虽然我们初步实现了点赞功能,不过有一个非常严重的问题,点赞业务包含多次数据库读写操作:

更重要的是,点赞操作波动较大,有可能会在短时间内访问量激增。例如有人非常频繁的点赞、取消点赞。这样就会给数据库带来非常大的压力。
怎么办呢?
4.1.改进思路分析
其实在实现提交学习记录的时候,我们就给大家分析过高并发问题的处理方案。点赞业务与提交播放记录类似,都是高并发写操作。
按照之前我们讲的,高并发写操作常见的优化手段有:
优化SQL和代码
变同步写为异步写
合并写请求
有同学可能会说,我们更新业务方点赞数量的时候,不就是利用MQ异步写来实现的吗?
没错,确实如此,虽然异步写减少了业务执行时间,降低了数据库写频率。不过此处更重要的是利用MQ来解耦。而且数据库的写次数没有减少,压力依然很大。
所以,我们应该像之前播放记录业务一样,采用合并写请求的方案。当然,现在的异步处理也保留,这样就兼顾了异步写、合并写的优势。
需要注意的是,合并写是有使用场景的,必须是对中间的N次写操作不敏感的情况下。点赞业务是否符合这一需求呢?
无论用户中间执行点赞、取消、再点赞、再取消多少次,点赞次数发生了多少次变化,业务方只关注最终的点赞结果即可:
用户是否点赞了
业务的总点赞次数
因此,点赞功能可以使用合并写方案。最终我们的点赞业务流程变成这样:

合并写请求有两个关键点要考虑:
数据如何缓存
缓存何时写入数据库
4.1.1.点赞数据缓存
点赞记录中最两个关键信息:
用户是否点赞
某业务的点赞总次数
这两个信息需要分别记录,也就是说我们需要在Redis中设计两种数据结构分别存储。
4.1.1.1.用户是否点赞
要知道某个用户是否点赞某个业务,就必须记录业务id以及给业务点赞的所有用户id . 由于一个业务可以被很多用户点赞,显然是需要一个集合来记录。而Redis中的集合类型包含四种:
List
Set
SortedSet
Hash
而要判断用户是否点赞,就是判断存在且唯一。显然,Set集合是最合适的。我们可以用业务id为Key,创建Set集合,将点赞的所有用户保存其中,格式如下:
KEY(bizId) | VALUE(userId) |
|---|---|
bizId:1 | userId:1 |
userId:2 | |
userId:3 |
可以使用Set集合的下列命令完成点赞功能:
# 判断用户是否点赞
SISMEMBER bizId userId
# 点赞,如果返回1则代表点赞成功,返回0则代表点赞失败
SADD bizId userId
# 取消点赞,就是删除一个元素
SREM bizId userId
# 统计点赞总数
SCARD bizId由于Redis本身具备持久化机制,AOF提供的数据可靠性已经能够满足点赞业务的安全需求,因此我们完全可以用Redis存储来代替数据库的点赞记录。
也就是说,用户的一切点赞行为,以及将来查询点赞状态我们可以都走Redis,不再使用数据库查询。
你会担心,如果点赞数据非常庞大,达到数百亿,那么该怎办呢?
大多数企业根本达不到这样的规模,如果真的达到也没有关系。这个时候我们可以将Redis与数据库结合。
先利用Redis来记录点赞状态
并且定期的将Redis中的点赞状态持久化到数据库
对于历史点赞记录,比如下架的课程、或者超过2年以上的访问量较低的数据都可以从redis移除,只保留在数据库中
当某个记录点赞时,优先去Redis查询并判断,如果Redis中不存在,再去查询数据库数据并缓存到Redis
4.1.1.2.点赞次数
由于点赞次数需要在业务方持久化存储到数据库,因此Redis只起到缓存作用即可。
由于需要记录业务id、业务类型、点赞数三个信息:
一个业务类型下包含多个业务id
每个业务id对应一个点赞数。
因此,我们可以把每一个业务类型作为一组,使用Redis的一个key,然后业务id作为键,点赞数作为值。这样的键值对集合,有两种结构都可以满足:
Hash:传统键值对集合,无序
SortedSet:基于Hash结构,并且增加了跳表。因此可排序,但更占用内存
如果是从节省内存角度来考虑,Hash结构无疑是最佳的选择;但是考虑到将来我们要从Redis读取点赞数,然后移除(避免重复处理)。为了保证线程安全,查询、移除操作必须具备原子性。而SortedSet则提供了几个移除并获取的功能,天生具备原子性。并且我们每隔一段时间就会将数据从Redis移除,并不会占用太多内存。因此,这里我们计划使用SortedSet结构。
格式如下:
KEY(bizType) | Member(bizId) | Score(likedTimes) |
|---|---|---|
likes:qa | bizId:1001 | 10 |
bizId:1002 | 5 | |
likes:note | bizId:2001 | 9 |
bizId:2002 | 21 |
当用户对某个业务点赞时,我们统计点赞总数,并将其缓存在Redis中。这样一来在一段时间内,不管有多少用户对该业务点赞(热点业务数据,比如某个微博大V),都只在Redis中修改点赞总数,无需修改数据库。
4.1.2.点赞数据入库
点赞数据写入缓存了,但是这里有一个新的问题:
何时把缓存的点赞数,通过MQ通知到业务方,持久化到业务方的数据库呢?
在之前的提交播放记录业务中,由于播放记录是定期每隔15秒发送一次请求,频率固定。因此我们可以通过接收到播放记录后延迟20秒检测数据变更来确定是否有新数据到达。
但是点赞则不然,用户何时点赞、点赞频率如何完全不确定。因此无法采用延迟检测这样的手段。怎么办?
事实上这也是大多数合并写请求业务面临的问题,而多数情况下,我们只能通过定时任务,定期将缓存的数据持久化到数据库中。
4.1.3.流程图
综上所述,基于Redis做写缓存后,点赞流程如下:

4.2.改造点赞逻辑
需要改造的内容包括:
tj-remark中所有点赞有关接口点赞接口
查询单个点赞状态
批量查询点赞状态
tj-remark处理点赞数据持久化的定时任务tj-learning监听点赞数变更消息的业务
由于需要访问Redis,我们提前定义一个常量类,把Redis相关的Key定义为常量:

代码如下:
public interface RedisConstants {
/*给业务点赞的用户集合的KEY前缀,后缀是业务id*/
String LIKE_BIZ_KEY_PREFIX = "likes:set:biz:";
/*业务点赞数统计的KEY前缀,后缀是业务类型*/
String LIKES_TIMES_KEY_PREFIX = "likes:times:type:";
}4.2.1.点赞接口
接下来,我们定义一个新的点赞业务实现类:

并将LikedRecordServiceImpl注释:
代码如下:
import static com.tianji.common.constants.MqConstants.Exchange.LIKE_RECORD_EXCHANGE;
import static com.tianji.common.constants.MqConstants.Key.LIKED_TIMES_KEY_TEMPLATE;
/**
* <p>
* 点赞记录表 服务实现类
* </p>
*/
@Service
@RequiredArgsConstructor
public class LikedRecordServiceRedisImpl extends ServiceImpl<LikedRecordMapper, LikedRecord> implements ILikedRecordService {
private final RabbitMqHelper mqHelper;
private final StringRedisTemplate redisTemplate;
@Override
public void addLikeRecord(LikeRecordFormDTO recordDTO) {
// 1.基于前端的参数,判断是执行点赞还是取消点赞
boolean success = recordDTO.getLiked() ? like(recordDTO) : unlike(recordDTO);
// 2.判断是否执行成功,如果失败,则直接结束
if (!success) {
return;
}
// 3.如果执行成功,统计点赞总数
Long likedTimes = redisTemplate.opsForSet()
.size(RedisConstants.LIKES_BIZ_KEY_PREFIX + recordDTO.getBizId());
if (likedTimes == null) {
return;
}
// 4.缓存点总数到Redis
redisTemplate.opsForZSet().add(
RedisConstants.LIKES_TIMES_KEY_PREFIX + recordDTO.getBizType(),
recordDTO.getBizId().toString(),
likedTimes
);
}
private boolean unlike(LikeRecordFormDTO recordDTO) {
// 1.获取用户id
Long userId = UserContext.getUser();
// 2.获取Key
String key = RedisConstants.LIKES_BIZ_KEY_PREFIX + recordDTO.getBizId();
// 3.执行SREM命令
Long result = redisTemplate.opsForSet().remove(key, userId.toString());
return result != null && result > 0;
}
private boolean like(LikeRecordFormDTO recordDTO) {
// 1.获取用户id
Long userId = UserContext.getUser();
// 2.获取Key
String key = RedisConstants.LIKES_BIZ_KEY_PREFIX + recordDTO.getBizId();
// 3.执行SADD命令
Long result = redisTemplate.opsForSet().add(key, userId.toString());
return result != null && result > 0;
}
}4.2.2.批量查询点赞状态统计
目前我们的Redis点赞记录数据结构如下:
KEY(bizId) | VALUE(userId) |
|---|---|
bizId:1 | userId:1 |
userId:2 | |
userId:3 |
当我们判断某用户是否点赞时,需要使用下面命令:
# 判断用户是否点赞
SISMEMBER bizId userId需要注意的是,这个命令只能判断一个用户对某一个业务的点赞状态。而我们的接口是要查询当前用户对多个业务的点赞状态。
因此,我们就需要多次调用SISMEMBER命令,也就需要向Redis多次发起网络请求,给网络带宽带来非常大的压力,影响业务性能。
那么,有没有办法能够一个命令完成多个业务点赞状态判断呢?
非常遗憾,答案是没有!只能多次执行SISMEMBER命令来判断。
不过,Redis中提供了一个功能,可以在一次请求中执行多个命令,实现批处理效果。这个功能就是Pipeline
中文文档:
不要在一次批处理中传输太多命令,否则单次命令占用带宽过多,会导致网络阻塞
Spring提供的RedisTemplate也具备pipeline功能,最终批量查询点赞状态功能实现如下:
@Override
public Set<Long> isBizLiked(List<Long> bizIds) {
// 1.获取登录用户id
Long userId = UserContext.getUser();
// 2.查询点赞状态
List<Object> objects = redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
StringRedisConnection src = (StringRedisConnection) connection;
for (Long bizId : bizIds) {
String key = RedisConstants.LIKES_BIZ_KEY_PREFIX + bizId;
src.sIsMember(key, userId.toString());
}
return null;
});
// 3.返回结果
return IntStream.range(0, objects.size()) // 创建从0到集合size的流
.filter(i -> (boolean) objects.get(i)) // 遍历每个元素,保留结果为true的角标i
.mapToObj(bizIds::get)// 用角标i取bizIds中的对应数据,就是点赞过的id
.collect(Collectors.toSet());// 收集
}4.2.3.定时任务
点赞成功后,会更新点赞总数并写入Redis中。而我们需要定时读取这些点赞总数的变更数据,通过MQ发送给业务方。这就需要定时任务来实现了。
定时任务的实现方案有很多,简单的适用于单体项目使用的例如:
SpringTask
Quartz
还有一些依赖第三方服务的分布式任务框架:
Elastic-Job
XXL-Job
此处我们先使用简单的SpringTask来实现并测试效果。
首先,在tj-remark模块的RemarkApplication启动类上添加注解:
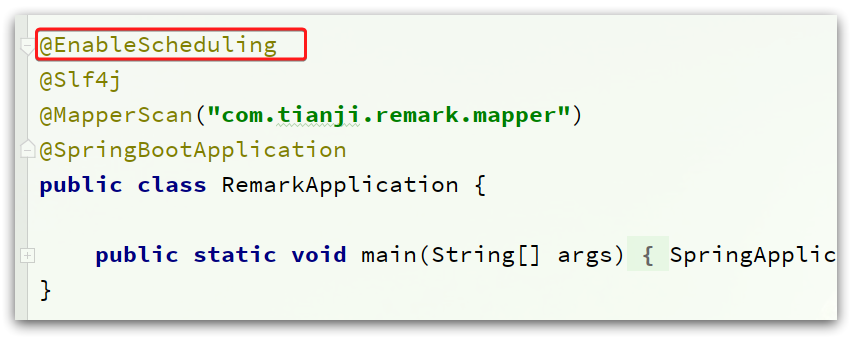
其作用就是启用Spring的定时任务功能。
然后,定义一个定时任务处理器类:

代码如下:
@Slf4j
@Component
@RequiredArgsConstructor
public class LikedTimesCheckTask {
@Value("${tj.remark.bizTypes}") //配置文件中动态加载
private String bizType;
private static final int MAX_BIZ_SIZE = 30;
private final ILikedRecordService likedRecordService;
/**
* 每20秒执行一次 将redis中 业务类型 下面的 某业务的点赞数量 发送消息到mq
*/
// @Scheduled(cron = "0/20 * * * * ?")// 每20秒执行一次
@Scheduled(fixedDelay = 20000)
public void checkLikedTimes() {
if (bizType == null || bizType.isEmpty()) {
return;
}
List<String> BIZ_TYPES = List.of(bizType.split(","));
for (String bizType : BIZ_TYPES) {
likedRecordService.readLikedTimesAndSendMessage(bizType, MAX_BIZ_SIZE);
}
}
}
由于可能存在多个业务类型,不能厚此薄彼只处理部分业务。所以我们会遍历多种业务类型,分别处理。同时为了避免一次处理的业务过多,这里设定了每次处理的业务数量为30,当然这些都是可以调整的。
真正处理业务的逻辑封装到了ILikedRecordService中:
public interface ILikedRecordService extends IService<LikedRecord> {
// ... 略
void readLikedTimesAndSendMessage(String bizType, int maxBizSize);
}其实现类:
@Override
public void readLikedTimesAndSendMessage(String bizType, int maxBizSize) {
// 1.读取并移除Redis中缓存的点赞总数
String key = RedisConstants.LIKES_TIMES_KEY_PREFIX + bizType;
Set<ZSetOperations.TypedTuple<String>> tuples = redisTemplate.opsForZSet().popMin(key, maxBizSize);
if (CollUtils.isEmpty(tuples)) {
return;
}
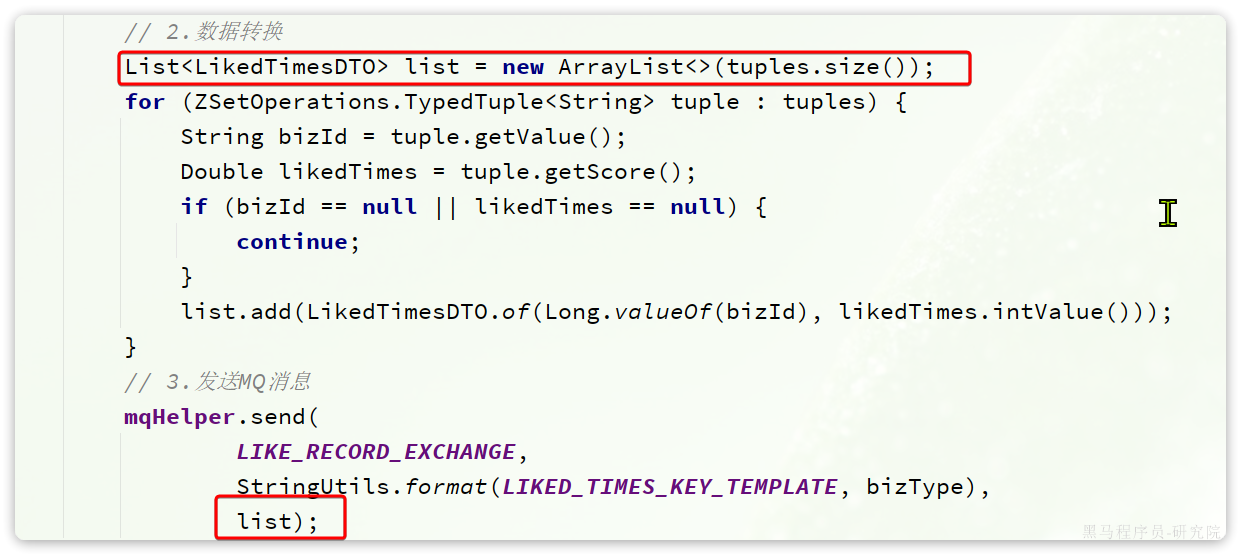
// 2.数据转换
List<LikedTimesDTO> list = new ArrayList<>(tuples.size());
for (ZSetOperations.TypedTuple<String> tuple : tuples) {
String bizId = tuple.getValue();
Double likedTimes = tuple.getScore();
if (bizId == null || likedTimes == null) {
continue;
}
list.add(LikedTimesDTO.of(Long.valueOf(bizId), likedTimes.intValue()));
}
// 3.发送MQ消息
mqHelper.send(
LIKE_RECORD_EXCHANGE,
StringUtils.format(LIKED_TIMES_KEY_TEMPLATE, bizType),
list);
}4.2.4.监听点赞数变更
需要注意的是,由于在定时任务中一次最多处理20条数据,这些数据就需要通过MQ一次发送到业务方,也就是说MQ的消息体变成了一个集合:
因此,作为业务方,在监听MQ消息的时候也必须接收集合格式。
我们修改tj-learning中的类com.tianji.learning.mq.LikeTimesChangeListener:
import static com.tianji.common.constants.MqConstants.Exchange.LIKE_RECORD_EXCHANGE;
import static com.tianji.common.constants.MqConstants.Key.QA_LIKED_TIMES_KEY;
@Slf4j
@Component
@RequiredArgsConstructor
public class LikeTimesChangeListener {
private final IInteractionReplyService replyService;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "qa.liked.times.queue", durable = "true"),
exchange = @Exchange(name = LIKE_RECORD_EXCHANGE, type = ExchangeTypes.TOPIC),
key = QA_LIKED_TIMES_KEY
))
public void listenReplyLikedTimesChange(List<LikedTimesDTO> likedTimesDTOs){
log.debug("监听到回答或评论的点赞数变更");
List<InteractionReply> list = new ArrayList<>(likedTimesDTOs.size());
for (LikedTimesDTO dto : likedTimesDTOs) {
InteractionReply r = new InteractionReply();
r.setId(dto.getBizId());
r.setLikedTimes(dto.getLikedTimes());
list.add(r);
}
replyService.updateBatchById(list);
}
}注意此处使用SpringTask实现的定时任务只适用于单体项目,微服务项目最好换成分布式任务调度框架如XXL-JOB等,避免出现分布式多个服务实例同时运行任务下的资源争抢问题。